做了下爬虫,所以记一笔。
## 在2020年的某一天,一个好好的前端开发,硬生生的搞成了爬虫开发,还是个不会python,只会nodejs的爬虫,太难了。
最开始做爬虫的时候,是按着前端开发所见到的来的。想着不过是调用调用再调用接口而已。直到我接触到了几个互联网大佬的公司,才发现事情并不简单。
第一个目标是一个公开的排行榜,很简单,只限制了请求频率,不超过这个频率,就是调用调用接口而已。
第二个目标也是一个公开的表单,只是数据不在接口里,而是在直接返回的原文件里。因为nodejs里没有dom操作,所以需要借用别的工具 cheerio,手感有点像jQuery。这个目标也不难,只需要研究好了这个网页的dom结构就好了。
第三个目标是一个需要登陆才能看到的数据,这里我先正常登陆,在开发者工具页面获取到token,再带上token去请求想要的数据,也…… 不是太麻烦,但是一开始没注意token是会失效的,过了几天再去看数据发现都爬到,因为token失效了。所以如果想要完全自动化,需要判断token是否失效,然后再自动登陆。
第四个目标就开始麻烦,还不是一般的麻烦——字体加密,去搜“爬虫 字体加密”,最典型的就是大众点评了。
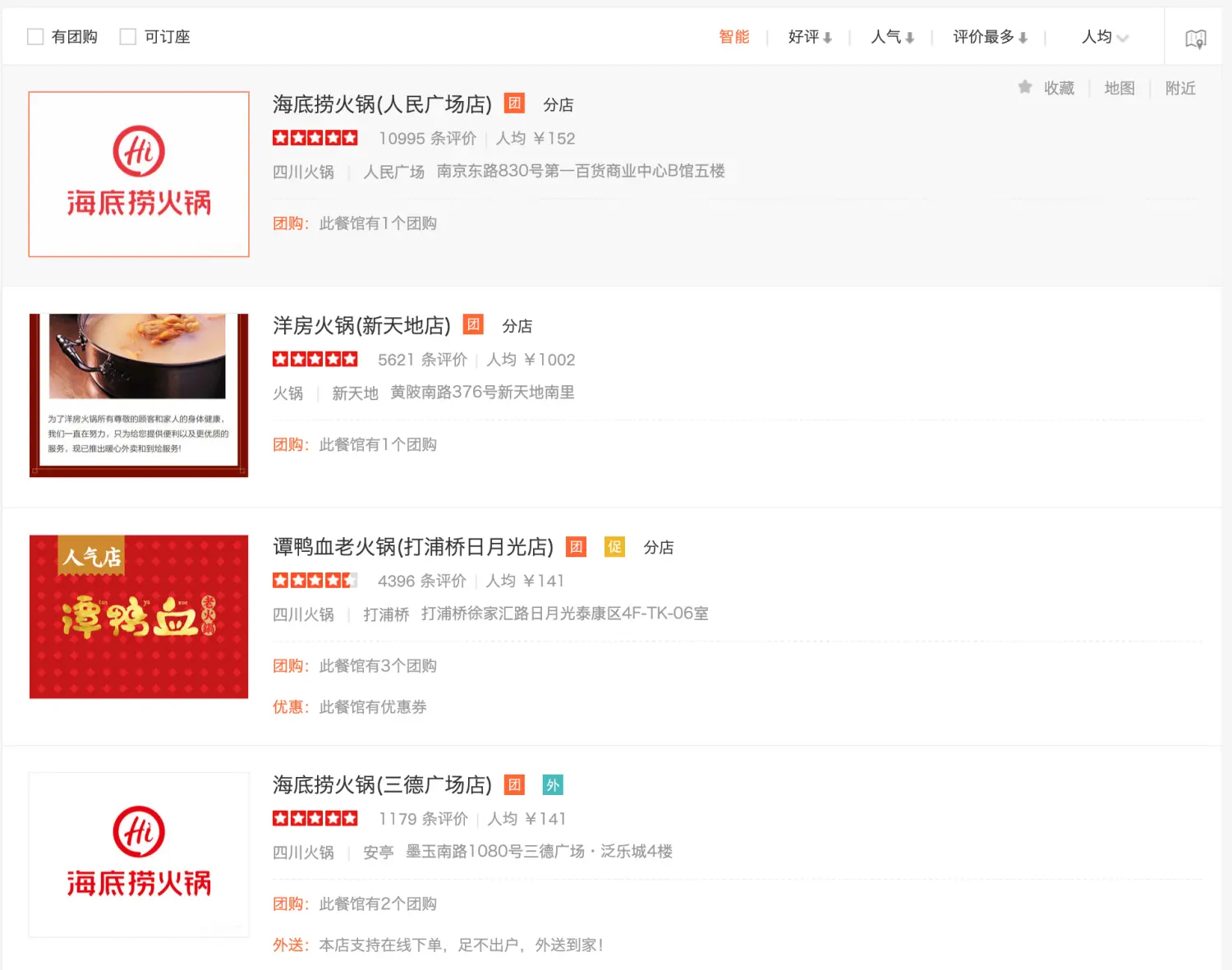
大众点评的页面看上去工工整整,看上去很好处理,打开开发者工具,发现数据是直接返回在html中的,所以得用上cheerio。但是仔细一看。
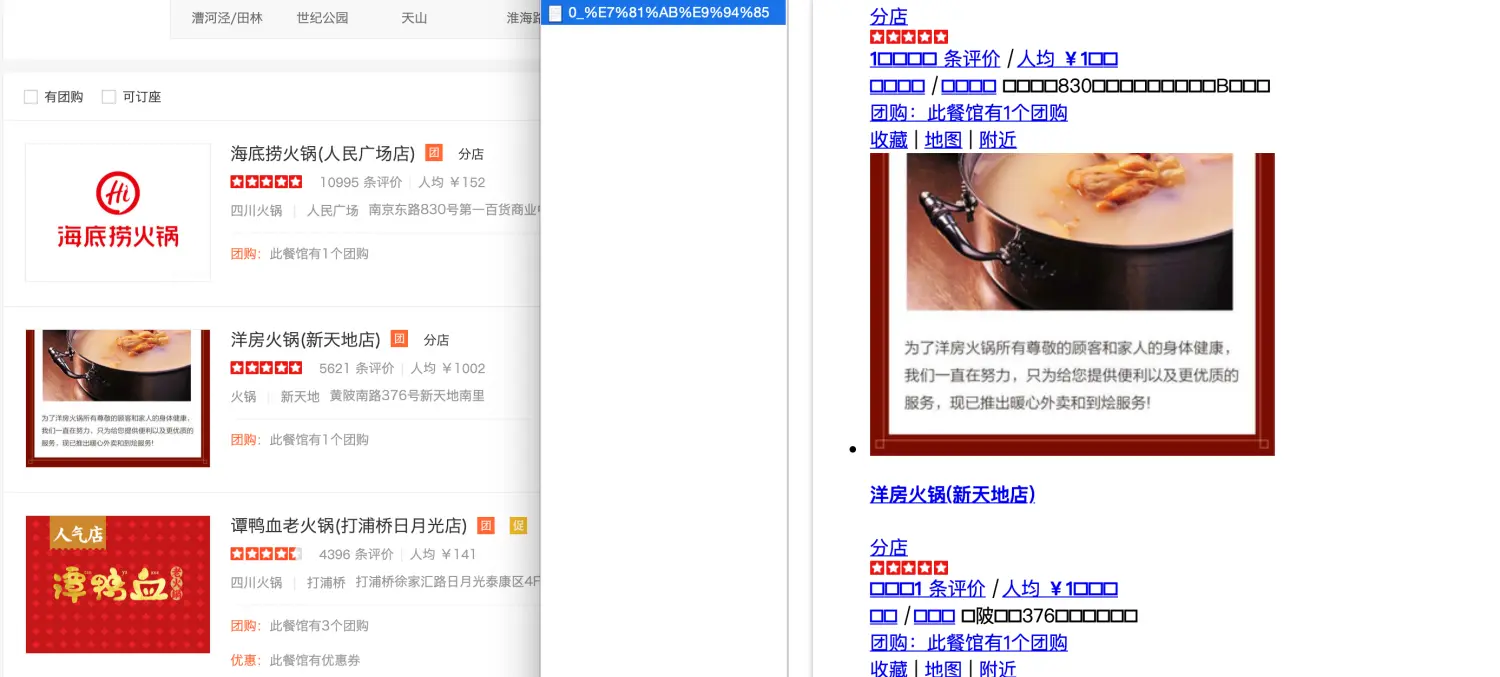
是我电脑出问题了吗?为什么都是呢?在通过检查元素看一下这些到底是啥。
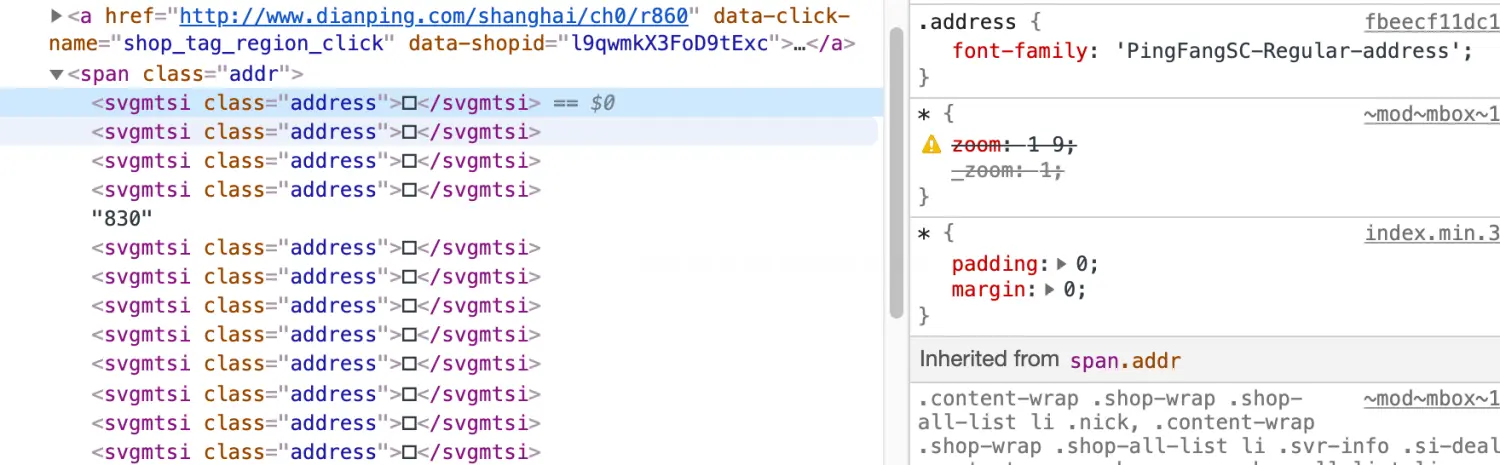
像极了我用iconfont的样子。
找到字体文件,下载字体文件,然后打开百度字体编辑器,上传下好的woff文件。(其实我用safari打开网友上传woff文件会报错,要先转换成ttf才行)

可以看到一个码对应一个字,可以自己扣一个字典出来。但是如果真要扣的话…… 要自己一个个手写,这一个woff文件就是600多个字,而这些字实际上是svg,不能复制只能手敲。因为只是体验一下,所以放弃了地址,只瞄准数字,10个字符而已,手打也不过如此。做好字典以后,就如第二个目标一样,用cheerio获取dom内容,然后将dom里的那些unicode按着字典一个个替换。然后,然后就完事啦!然而,事情并没有那么简单…… 这该死的字体竟然会更换的!虽然不太清楚频率(我遇到的第二天就换了),但是就算只扣10个字,天天扣,那也足够傻了。
再搜了不少资料后,发现python有个fonttools,然而我不会!继而去npm上搜,搜到了一个node-fonttools,其本质还是调用python,只是进行了一下封装,可以方便的给js来用。之后就是找到css,下载里面引用的字体包,然后将字体包丢给node-fonttools,让其识别文字,再提炼出字典,再进行上面的操作。
在一些别的爬虫项目中,还遇到过对ip限制特别严格的情况,在这个情况下就需要自己弄个ip池,请求一两下就换个ip继续搞。用来识别用户的还有user-agent,这也可以弄个池子,请求一次换一个。而对那些需要用户登陆才能访问的数据,在某些情况下,还需要有个用户的池子。这些东西都是为了不让对方认出来并且拦住我的请求。
在学习爬虫的过程中,还遇到过一些公司对自家数据安全一点也不放在心上…虽然对爬虫开发的我来说是件好事,但是对前端开发和也写点后端内容的我来说,也确实是警钟,让我对数据安全、反爬虫这方面又涨了点知识。